robots.txtは、ウェブサイトのルートディレクトリに配置されるテキストファイルで、検索エンジンのクローラーなどのウェブロボットに対し、ウェブサイトのどのページやセクションにアクセスおよびインデックス作成を許可するかを指示します。このファイルは、これらの自動化されたボットに対する一連の指示として機能します。
robots.txtの使用例:
- 特定のディレクトリのDisallow: User-agent: * Disallow: /private/ これは、すべてのロボットに「/private/」ディレクトリとそのコンテンツへのアクセスを許可しないように指示します。
- 特定のロボットを許可し、他のロボットをDisallowする: User-agent: Googlebot Allow: / User-agent: * Disallow: / これは、Googleのクローラーにはすべてのページへのアクセスを許可し、他のすべてのロボットにはアクセスを拒否します。
- サイトマップの場所を指定する: Sitemap: https://example.com/sitemap.xml これは、ロボットにウェブサイトのサイトマップの場所を指示し、効率的なサイトのクロールを支援します。
- 特定のファイルタイプへのアクセスをDisallowする: User-agent: * Disallow: /*.pdf$ これは、ロボットがウェブサイト上のPDFファイルにアクセスするのを防ぎます。
robots.txtは公開されているファイルであり、機密情報を隠すために使用すべきではないことを覚えておいてください。誰でも簡単に閲覧できます。
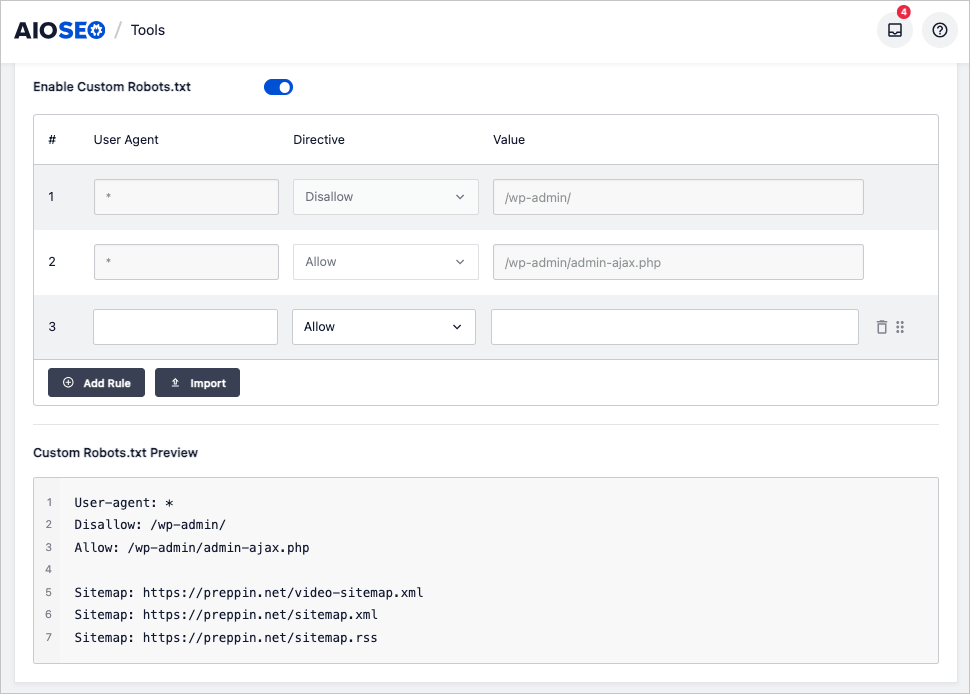
WordPressのrobots.txt
All in One SEOは、使いやすいrobots.txtエディターを提供しています。コードを扱う必要はありません。ユーザーはフォームフィールドに入力することでrobots.txtファイルを編集できます。
関連: