Robots.txt is a text file placed in the root directory of a website that instructs web robots (such as search engine crawlers) which pages or sections of the website they are allowed to access and index. This file acts as a set of instructions for these automated bots.
Examples of how robots.txt is used:
- Disallowing specific directories: User-agent: * Disallow: /private/ This tells all robots not to access the “/private/” directory and its contents.
- Allowing specific robots while disallowing others: User-agent: Googlebot Allow: / User-agent: * Disallow: / This allows Google's crawler to access all pages, while disallowing all other robots.
- Specifying the location of the sitemap: Sitemap: https://example.com/sitemap.xml This directs robots to the location of the website's sitemap, which helps them efficiently crawl the site.
- Disallowing access to specific file types: User-agent: * Disallow: /*.pdf$ This prevents robots from accessing any PDF files on the website.
Remember that robots.txt is a publicly accessible file and should not be used to hide sensitive information, as it can be easily viewed by anyone.
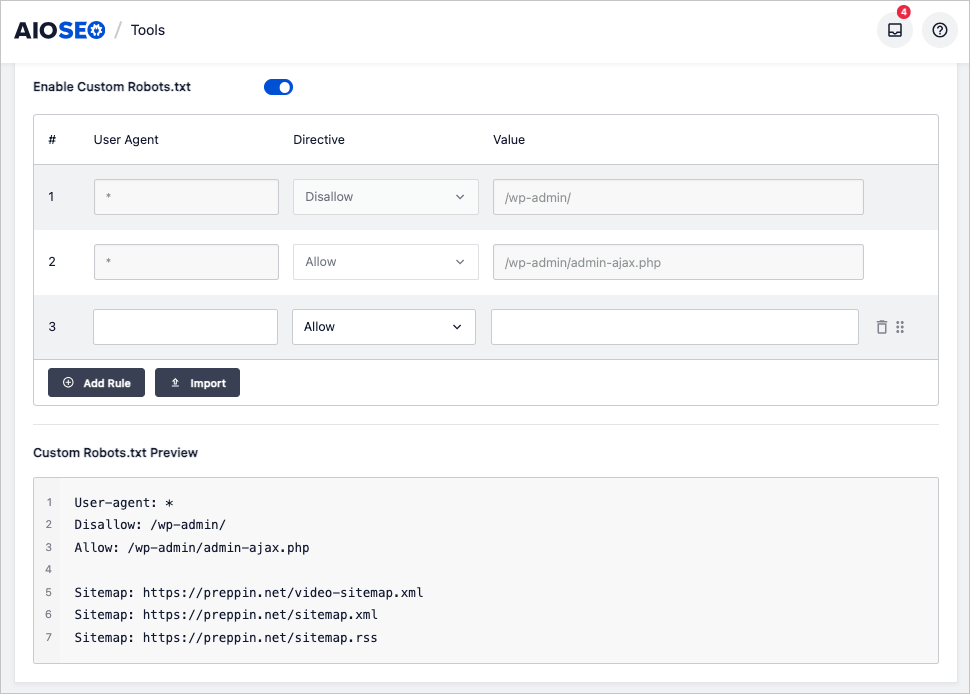
Robots.txt in WordPress
All in One SEO provides a user-friendly robots.txt editor. There's no need to deal with code. Users can edit their robots.txt file by filling in form fields.
Related: